
 vicevirus’ Blog
vicevirus’ Blog

Hello everyone! Before we start,
Thanks to everyone who has been using the website for the support! I hope it's been helpful.
Disclaimer : The university timetable that I built is unofficial, and is not endorsed by my university (UNISEL) in any way.
Discovering the problem
First of all, let me share on what we students of Universiti Selangor (UNISEL) needs to do at the start of every semester. (I am pretty sure it applies to other universities too)
For every semester, we have to register for subjects through a system called “e-student system”. In the system, students could add and drop the subjects that they want to take for that specific semester.
And, we also have to make sure the subject’s time that we are adding are not clashing with other subjects.

Well here comes the difficult part..
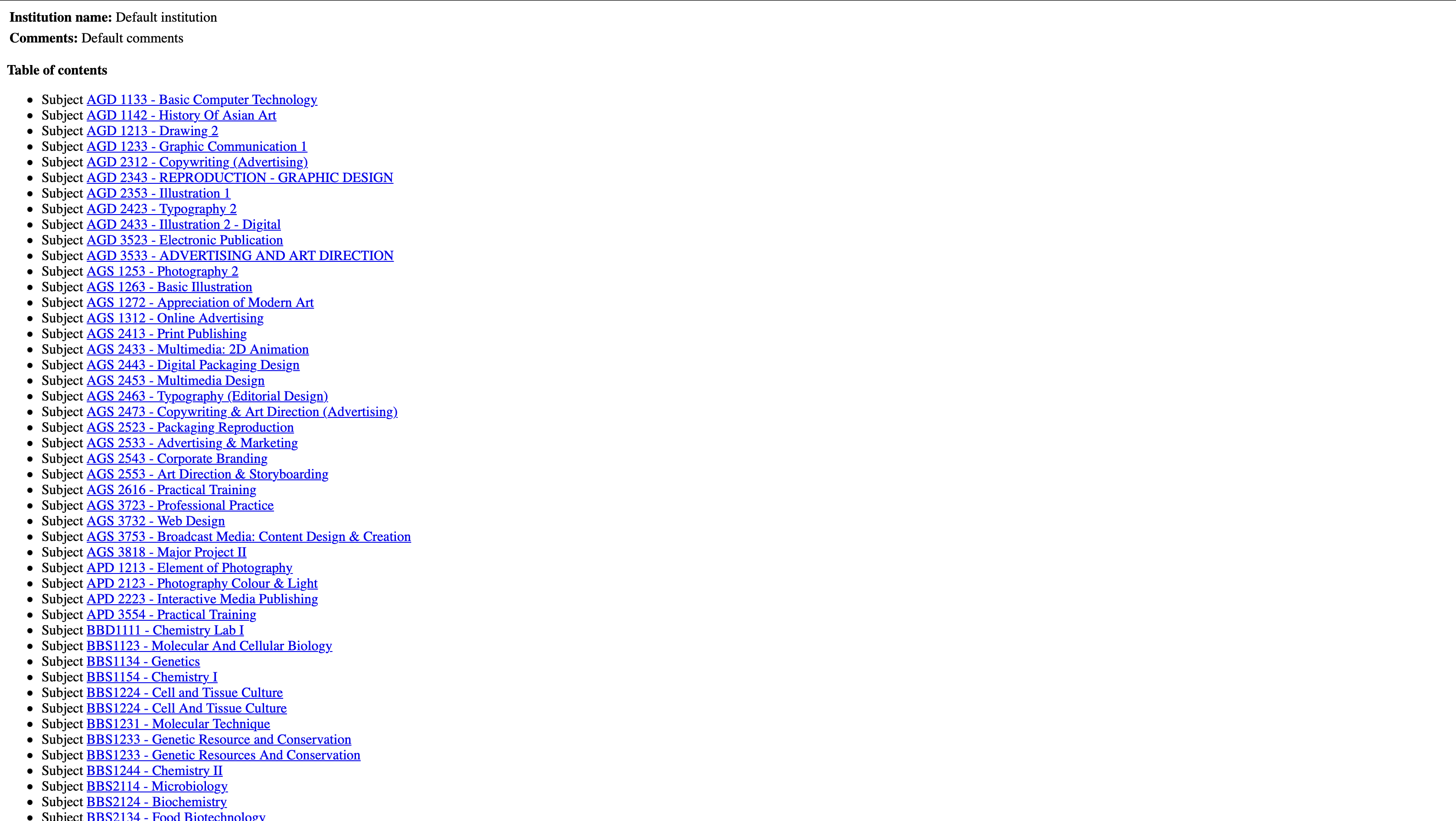
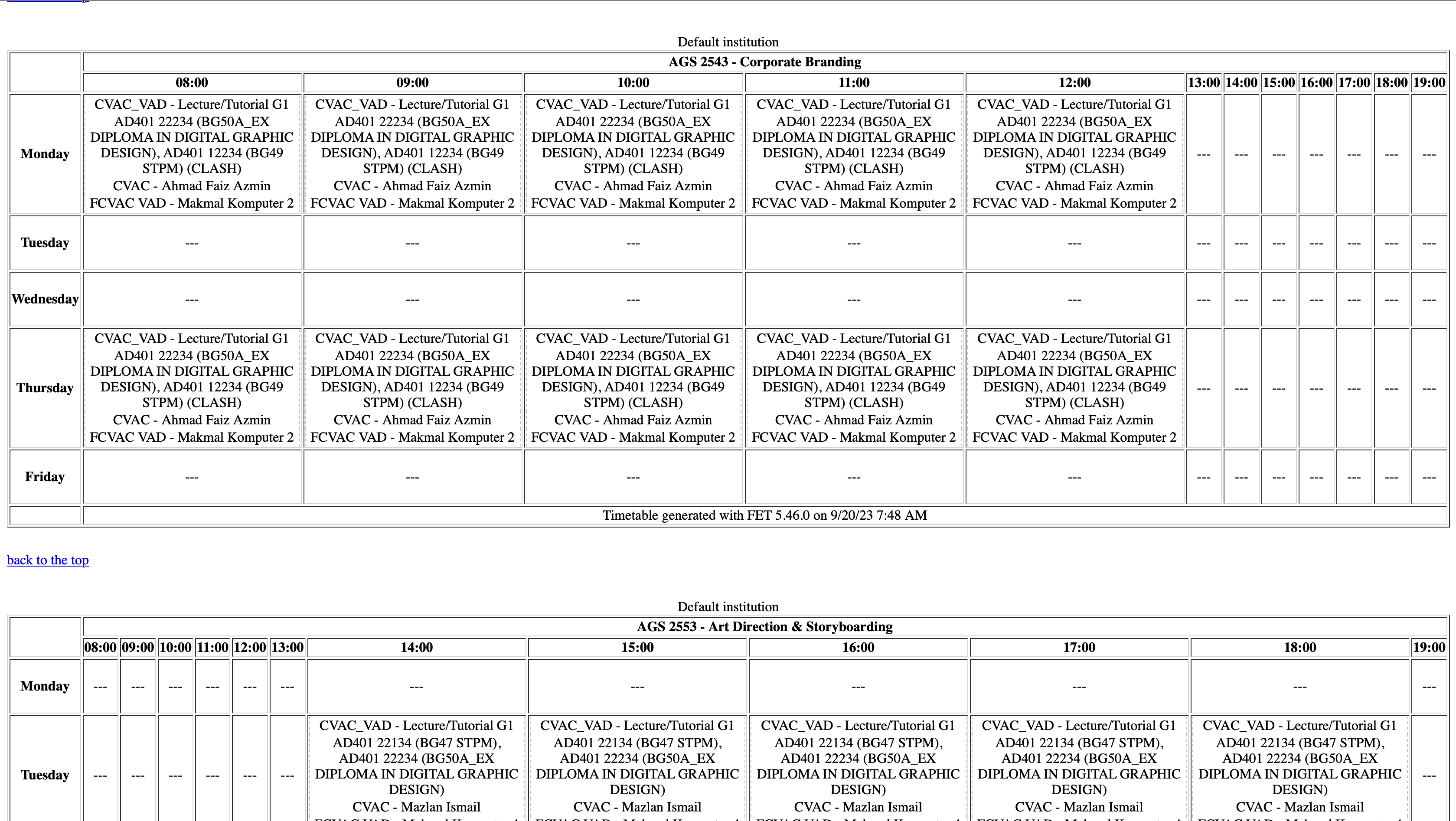
To check for the subject’s time, we have to navigate through an official timetable website called “UNISEL eTimetable”. There were a few experience on the website that I didn’t like and I find it difficult to navigate through while trying to find my subjects.
The difficulties that I’ve had with the “UNISEL eTimetable” is that:
- The page renders 100+ subjects tables in one HTML.
-
You have to use
CTRL+F(or scroll manually) to find your subjects. - Navigation can be laggy in my phone sometimes (weak phone 🥲)
Finding a solution
After I’ve discovered the problem. I was thinking of solutions on how I could make the timetable website better for me and the students in my uni.
Maybe I could make my own timetable website with my own design and functionalities..?

Okay that’s not a problem..
BUT, HOW DO I GET THE TIMETABLE DATA?
I’ve tried to contact the UNISEL IT Department (CICT) to see if I could get raw data of the timetable but, I didn’t get any response from them.
So… what next?
Well.. I guess web scraping is the only thing I could do now to obtain the raw data.
(From what I’ve heard it’s actually illegal to scrape certain websites)

Plan:
-
Get raw data by scraping the UNISEL eTimetable website and parse it to
JSON. -
Build an
APIthat serves the timetable data inJSONformat allowing the timetable data to be fetched and make it open for everyone. -
Display it in front-end framework using framework such as
Vue/React.
Hmm simple plan for a simple website, it should work, right…?
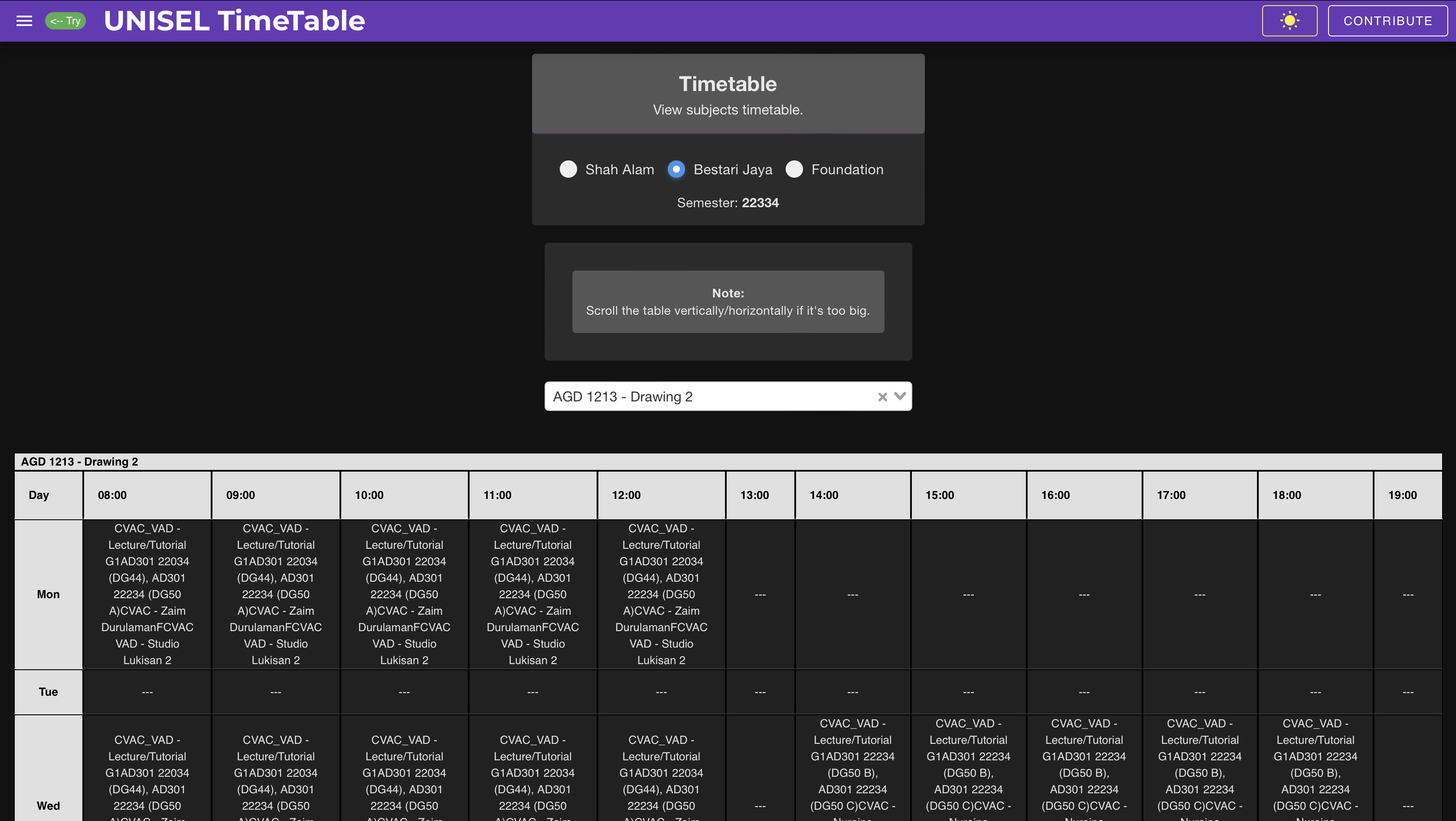
Building the website
For the scraping script, I chose to use beautifulsoup and Python.
For the website’s front-end, I chose to use Vue.
For the website’s back-end, I chose to use FastAPI.
Why Vue?
No reason. Last time I used Vue was in 2018, trying to get into it back again and sees how much it have changed.
Why FastAPI?
I built the scraper script on Python, and I believe the script’s integration into the API will be much more easier if they used the same language. + I’ve never tried FastAPI before and I heard really good things about it.
Everything went smoothly and it took me 3-4 days to build the simple website.
Deploying Plans + Realization
Great! Now we have a working website running locally. We can now deploy it outside!
But wait…
@app.get("/timetable_data/{campus}/{semester}")
async def read_timetable_data(campus: str, semester: str):
semester = validate_semester(semester)
timetable_data = await get_timetable_data(campus, semester)
return timetable_dataasync def get_timetable_data(campus: str, semester: int):
file_name = f"timetable_data_{semester}_{campus}.json"
# Check if file exists, update timetable until it is available
while not os.path.exists(file_name):
result = subprocess.run(["python3", "scraper.py", "--semester", str(
semester), "--campus", campus], capture_output=True, text=True)
if result.returncode != 0:
raise HTTPException(
status_code=500, detail=f"Error occurred while updating timetable: {result.stderr}")
await asyncio.sleep(10)
# Load timetable data from file
async with aiofiles.open(file_name, "r") as file:
timetable_data = json.loads(await file.read())
return timetable_data
/timetable_data route, it will check if the timetable have already been scraped and exists inside the folder. Else it will call the scraper.py script and do the scraping if the timetable data doesn’t exist.
I’ve just realized that the code above can be expensive to run multiple times especially since I only plan on deploying it on my 1GB 1/8 OCPU free Oracle Cloud Instances. (Cheapo and broque)
Imagine running this multiple times and you have a lot of users. It will be a big performance issue and worse case, the server won’t be able to keep up with all the requests and it will crash..
(It was no fun seeing people unable to view/enjoy what you have built)
Well… can we have solution to this?

Realization Solution 1
Well……. let’s have some caching and load-balancing, and buy a better DigitalOcean Droplet Instance (Server/VPS).
So now, I have a total of 2 free Oracle Cloud Instances and 1 DigitalOcean Droplet.
(3 instances total)
During this time, I’ve hosted everything on my DigitalOcean Droplet 2GB mem 1VCPU ($12.00 per month)
and also on 2 of my Oracle Cloud Instances with 1GB mem 1/8 OCPU each (Free)
Things I’ve implemented:
- Redis (Caching) (1 for each server, tried to use Sentinel, but couldn’t set it up properly)
- Nginx (Load Balancing) (and little bit of caching) (1 master and 2 slave) (Least conn)
Nginx config for reference
https://github.com/vicevirus/UNISEL-TimeTable-REST-Scraper/blob/main/nginx_config
Testing with Apache JMeter (with Redis and Nginx)
- 300-500 concurrent requests without crashing.
- More requests will crash one of the server.
Testing with Apache JMeter (without Redis and Nginx)
- 100-200 concurrent requests without crashing.
and based on the results above, the performance did improve! Yay!

Realization 2
But wait.. do I realllllyy need all these caching and load-balancing stuff for a simple website that fetches and displays timetable data. And moreover we have a running cost of $12.00 per month.
So back to… can we have a solution to this? Can we run it with zero cost?
Realization 2 Solution
My solution to this, is to host the timetable data inside my Github repo instead of hosting my own API. and using Vercel.
Yes, that is the best solution I guess. Everything will be relied on and fetched from the Github and Vercel server. I don’t have to think about having too many requests or users.
The next thing I did was, I created a scraper script to check if there is changes in timetable data in the original UNISEL eTimetable website, do updates, scrape the data and upload it to my Github Repo.
And then, put the script inside both of my free Cloud Oracle Instances, running with cron every 5 minutes.
Scrape and upload to repo script:
https://github.com/vicevirus/unisel-timetable-hosting-data/blob/main/scrapeRepo.py

Plus it’s just a pet project lul.
State of the project now
I have added some new features, localstorage caching and changed the project to use Nuxt for better SEO and PWA implementation.
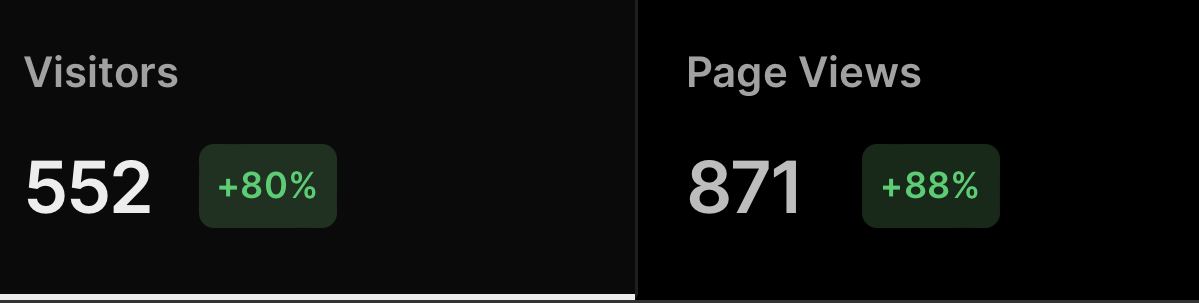
The website has been launched for 2 semesters now, and it has reached 500+ views/users every semester. (I shared the link to the website in most student groups)
You may visit the website here :
Nuxt Repo :
UNISEL Timetable data :
Conclusion
It was a very good learning experience working through the front-end and back-end.
Here’s what I’ve learned from this project:
- Don’t over-engineer stuff unless you need to.
- Measure and expect how much traffic to your website.
- In my case, I’ve never get concurrent requests of 500+. Users usually visit by interval.
- Find ways to make things free or lower the cost.
I hope students and lecturers of my uni could make use of the data available. Be it a final year project, personal project, feel free to do anything useful with it + it’s not mine, I scraped it :P
Thanks for reading!